Image Segmentation Using K-means Clustering Algorithm
Overview
K-means clustering was chosen to automatically identify flooded areas due to the small dataset size (69 images), lack of ground truth, and distinct visual features of flooded areas (brown sediment-laden water).
The algorithm groups data points based on similarity. When only image data is used, this similarity is based on color; when additional features are introduced, the similarity is calculated based on the combination.
Each image undergoes default K-means clustering with standardized data after removing invalid pixels (clouds and shadows). Four optimizations are then applied, utilizing combinations of PCA, NHD flowline data and NDWI data
Result ID: 45358 (Default vs. Best Optimization)
| Option | K-means Result |
|---|---|
| Default Cluster 1 includes the flooded area with noisy pixels. |

|
| NDWI feature with PCA Cluster 2 includes the flooded area with less noisy pixels. |
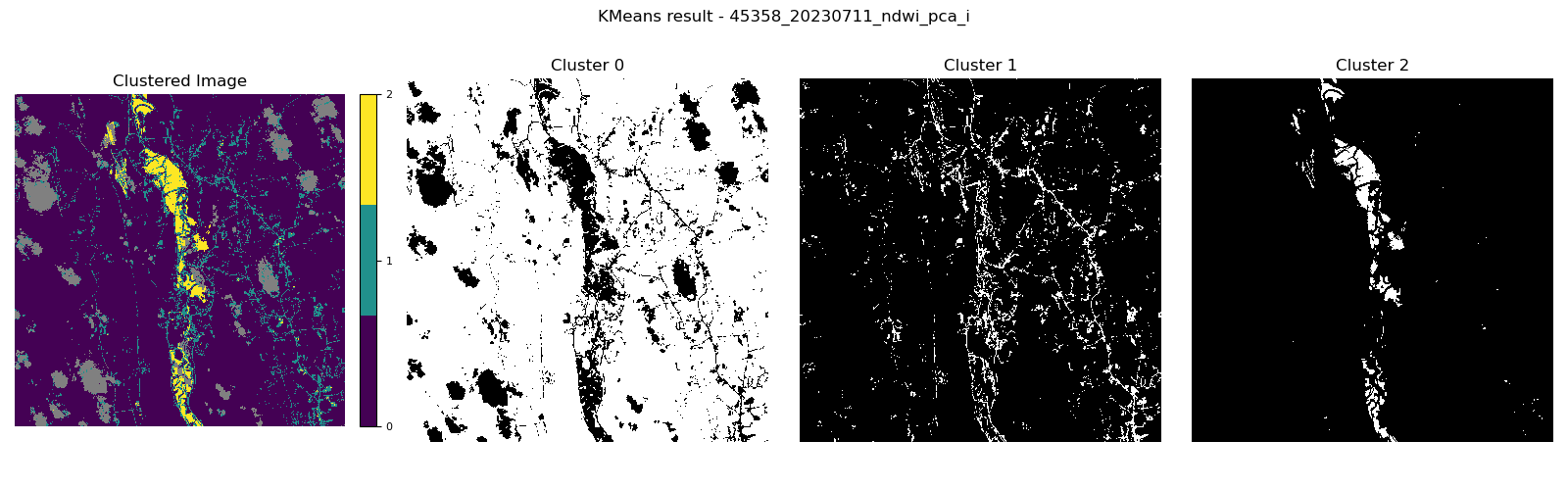
|
* More details can be found in the report.